複雑な環境におけるRAGアーキテクチャの進化
ご挨拶
平素より大変お世話になっております。
株式会社DXビジョンでございます。
私たちは、データサイエンティストとフルスタックエンジニアによる精鋭チームとして、
AI技術の社会実装を迅速かつ実践的に推進しております。
本日は、近年注目を集めているRAG(Retrieval-Augmented Generation)技術について、
その背景と活用方法をご紹介させていただきます。
目次
RAG技術概要
大規模言語モデル(LLM)とRAG(検索拡張生成)技術の統合により、スマートカスタマーサポートや医療診断支援、金融リサーチなどで知識検索型のQAシステムが実用化されていますが、企業内の複雑なナレッジ活用では、情報が異なる段落・文書・データソースに分散しているため、従来のRAGでは意味的に関連付けて統合し、正確な回答を生成することが難しくなっています。こうした課題に対しては、セマンティックな関連性を捉える高精度な検索、知識断片の統合、マルチモーダルなデータ融合、そして文脈全体を理解した推論技術の高度化が求められています。

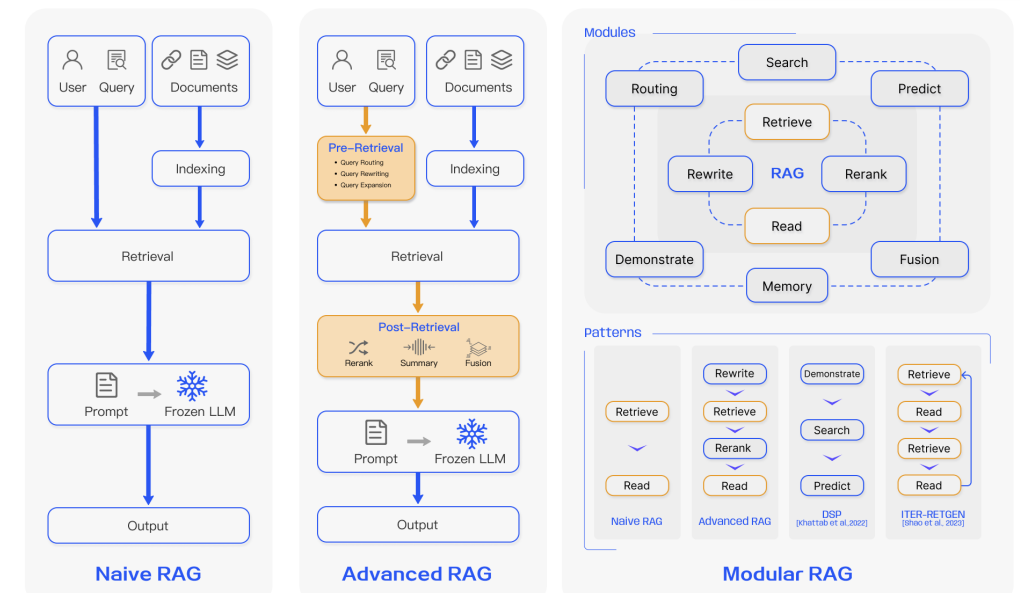
RAGの形態
RAG(検索拡張生成)の進化に伴い、朴素な初期型から高度なRAG、さらにモジュール化されたRAGへと多様な形態が登場しています。基本構成は常に「インデックス作成・検索・生成」の3段階を軸としていますが、高度なRAGではその前後に処理工程が追加され、モジュール型RAGではこれらが5つのフェーズに細分化され、各工程の理論・技術的な最適化が進められています。特にインデックス工程では、チャンクの分割最適化が多くの研究で注目されており、モジュール化をベースに多様な応用シナリオに対応するRAGの派生型が提案されています。また、ナレッジグラフを活用して情報を構造化し、概念・関係性を整理するGraph RAGのような応用も進展しており、組織的・体系的な情報抽出手法として注目を集めています。
RAG技術とは?
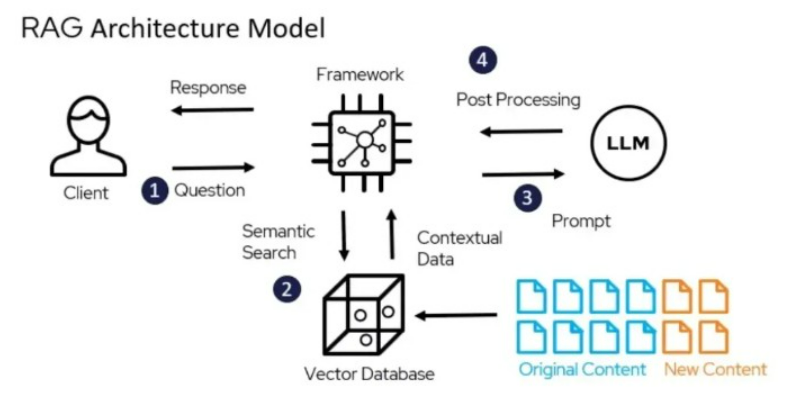
大規模言語モデル(LLM)は登場初期から「ハルシネーション(幻覚)」と呼ばれる問題を抱えており、その主因はモデルが最新情報を訓練時に学習しておらず、実運用時にも求められる知識を適切に提供されていない点にあります。特に新しい事象に関する質問に対して、誤った情報を返す傾向が強くなります。こうした課題を解決するため、私たちは外部に知識ベースを構築し、RAG(検索拡張生成)フレームワークを活用して、大規模モデルに必要なコンテキストを動的に取得・反映させ、適切に生成された回答としてユーザーに返す仕組みを整えました。
RAGの活用シーン
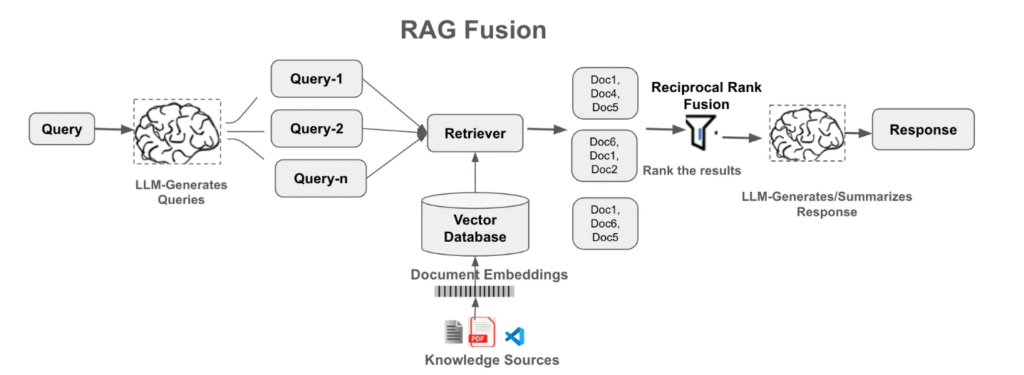
RAG(検索拡張生成)は、以下のような典型的な活用シーンで実績があります。適用の可否を判断する際の重要なポイントは、対象となる知識や情報が動的かつ頻繁に更新されるかどうかです。このような場合、RAGはほぼ不可欠な技術といえます。もちろん、大規模言語モデルを微調整したり、私有データで蒸留したりする方法もありますが、コストやスピードの面ではRAGの方が圧倒的に即効性が高いのが利点です。例えば、スマートカスタマーサポートの分野では、製品情報が日々更新されますが、RAGによって外部の製品知識ベースを構築しておけば、内容が変化しても常に最新情報を参照してユーザーの質問に回答できます。
複雑なシナリオにおける課題:異種知識(ヘテロジニアスナレッジ)
RAG(検索拡張生成)を活用する実環境では、単純なFAQや文章検索にとどまらず、より複雑なシナリオが求められます。特に課題となるのが「異種知識」の処理です。異種知識とは、形式・構造・表現が異なるさまざまな情報源を指し、その中でも今回は「構造のばらつき(離散性)」と「モダリティの多様性(テキスト・画像・音声など)」の2点に着目します。たとえば、ある企業内の知識にはPDFマニュアル、表形式のデータ、チャットログ、図面、画像などが混在しており、これらを一貫してRAGで扱うには、それぞれのデータ特性を理解し、適切に前処理・意味統合する技術が求められます。
構造の離散性
例えば、ある長い社内報告書があります。最初の方に「担当者の田中太郎は今年で35歳です」と書かれていて、最後の方には「太郎さんのこれまでの活躍は素晴らしいものでした」と記載されています。この「田中太郎」と「太郎さん」が同じ人だと理解して、文書全体の情報をつなげるのは簡単ではありません。従来のRAG技術は文書を小さな区切り(チャンク)に分けて処理しますが、区切り方が適切でないと、関連情報がバラバラになり、AIは全体像を把握できず、ユーザーには断片的な回答しか返せなくなります。このように、情報が文書内や複数の文書に散らばっている状態が「構造の離散性」の問題で、これを解決することが大きな課題となっています。
学習モデルの多様性
学習モデルの多様性は、従来のRAG技術は主にテキストデータの処理に特化していましたが、最近はマルチモーダル(複数のモデルを扱う)技術も登場しています。しかし、すべての異なるモデルを効率よく扱える理想的なRAGフレームワークはまだ確立されていません。このモデルの多様性によって生じる課題は大きく2つあります:
1.マルチモーダル検索
テキストを入力すると関連する画像や動画、表など異なる形式の情報も同時に検索できること。
2.クロスモーダル検索
例えば、テキストから画像を検索したり、逆に画像から関連するテキストを検索したりする機能です。
異種知識に対応するため業界最新のアプローチ
異種知識の課題への対応として、構造がばらばらな情報(構造の離散性)には、関連する段落を動的に統合する手法や、知識グラフによって情報同士の関係を可視化・整理する方法が提案されていますが、具体的な統合アルゴリズムの詳細はまだ限定的です。また、異なる形式のデータ(模態の多様性)に対しては、テキスト・画像・音声などをそれぞれ適切に処理し、最終的に統合して生成に活かす「マルチモーダルRAG」などの手法が注目されています。最近の研究では、GPT-4o や Gemini のようなマルチモーダル対応モデルや、グラフベースの検索・生成手法(例:G-RAG、Entity-aware Retrieval)などが登場し、異種知識の取り扱いに向けた実践的なアプローチが進みつつあります。
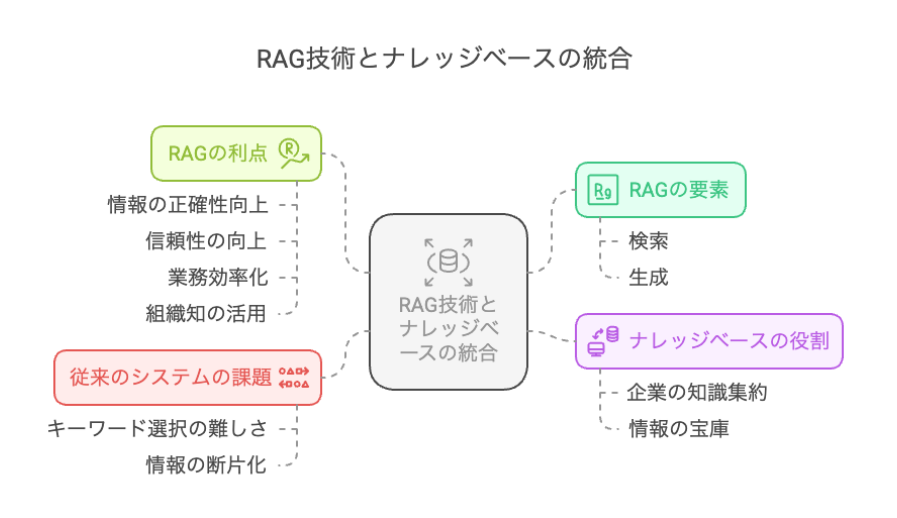
知識融合と統一セマンティクスによる次世代RAG構造
融合ナレッジベース:異種データを論理的に統合する中核基盤
融合ナレッジベースとは、指標情報、構造化データ、文書、画像といった多様で異種なデータを知識融合技術によって一元化・論理的に統合する基盤です。この融合プロセスでは、文書に対しては解析ツールとセクション分割技術によりメタデータを抽出し、リレーショナルデータベースに対しては指標情報や構造情報を取り出します。加えて、可視化ツールによりユーザーがデータ間の関係性を理解しやすくする工夫もされています。このように構築された融合ナレッジベースは、多様な粒度・モダリティの情報を含む論理的なストレージ単位としてアーキテクチャの基礎を成します。ただし、物理的なデータ保存先は変更せず、例えば文書は依然としてベクトルDBに、構造化データは元のMySQLやPostgreSQLに保持され、そのメタ情報のみが融合ナレッジベースに格納されます。製品としては、文書ナレッジベース、ウェブナレッジベース、指標ナレッジベースなどを単体で構築できるほか、既存のそれらを論理的に集約して融合ナレッジベースとして再編成することも可能です。さらに、教育など特定分野においては、教師・生徒・試験問題といったエンティティとその関係性を事前に定義することで、後段の統一セマンティック層構築の基礎が整います。
統一知識グラフにおける生成プロセス
統一知識グラフを活用するにあたっては、まず「どのように生成するか」を検討し、その後に「どのように利用するか」を考える必要があります。生成プロセスは図で表現できますが、左端には文書、画像、動画、リレーショナルデータベースなど、さまざまなモダリティのデータが存在します。これらの異なるモダリティに応じて、知識グラフに取り込む要素も異なります。たとえば文書データに対しては、簡易版のGraph RAG(Graph RAG Lightなど)を用いて、関心のあるエンティティや関係を抽出します。すべての内容を抽出するとコストや性能面での負荷が大きくなるため、事前に関心のある情報を明確にしておくことが重要です。これは、前段で構築した融合知識ベースにおいて、解決すべき業務課題や対象とするドメインモデルを明確にしておくことと深く関係しており、文書内容の抽出をより効率的かつ効果的に行うための基盤となります。
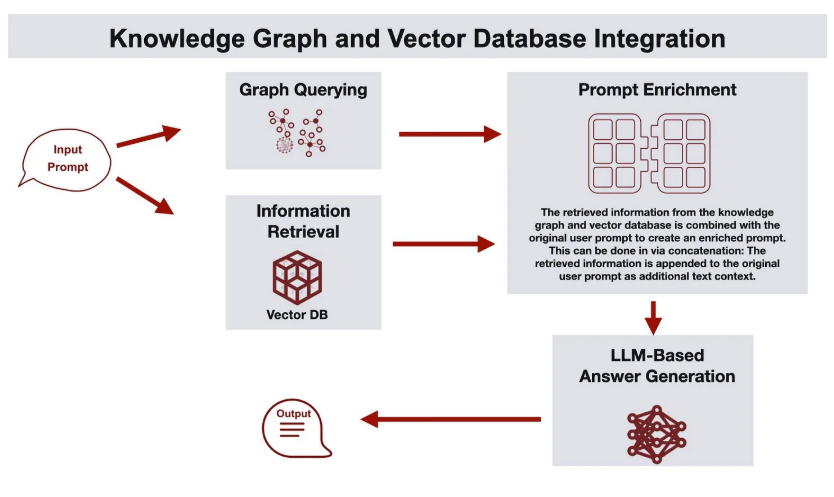
統一知識グラフにおける検索プロセス
統一知識グラフを活用する際、まずユーザーが質問やタスクの要求を提示すると、システムはベクトルデータベースで関連するエンティティや関係を検索し、ユーザーの意図に含まれる対象を意味的に把握します。次に、そのエンティティや関係を起点として、統一知識グラフ内で二跳(2ホップ)や三跳(3ホップ)の拡張クエリを実行し、関連するサブグラフを抽出します。拡張の深さは用途に応じて調整可能ですが、一般的には二跳検索で十分であり、三跳以上はデータ量が膨大になりやすいため注意が必要です。こうして得られたサブグラフにより、質問に関連する他のエンティティや関係性が明確になり、より適切で包括的な回答生成の基盤が構築されます。
業務適用の実践事例
事例1.病院における電子カルテ検索とスマート問答システムの実践事例
実際の運用例として、ある日本の病院での電子カルテ検索およびスマート問答システム導入事例をご紹介します。近年、インフルエンザや新型呼吸器感染症の流行が繰り返し発生し、医療現場は大きな負担を強いられています。患者は「診察は数十秒、待ち時間は数時間」といった状況に直面し、医師側も過去の患者の症状や治療経過を迅速に把握して、的確な診療を行いたいという課題を抱えていました。
この課題解決のため、当システムでは融合ナレッジベースと統一セマンティック層を活用しています。融合ナレッジベースには、患者情報、処方記録、入院履歴などの構造化データと、電子カルテの自由記述テキストデータが統合されています。統一セマンティック層では、「発熱」を体温37℃以上40℃未満と定義し、関連する症状や医療概念を体系化しました。
さらに統一知識グラフを構築し、患者を中心に処方、入院記録、手術履歴などのエンティティと電子カルテから抽出した症状や治療内容、回復状況を紐づけています。たとえば、ある患者ノードに対して「気管支炎」や「インフルエンザ」といった診断名、投薬内容、治療効果が関連付けられています。
実際の運用では、医師が「山田太郎さんの発熱と咳に対する治療法を知りたい」と質問すると、システムは過去1ヶ月間の関連患者データをベクトル検索で抽出し、知識グラフから該当するサブグラフを取得。電子カルテの詳細情報と組み合わせた上で、総合的な治療提案を生成します。これにより、医師は過去の類似症例の治療法を参照しながら、山田さんに最適な診療方針を検討することが可能となっています。
事例2.銀行のリスク指標監督分析アシスタントの実践事例
もう一つの具体的な事例は、ある日本の銀行におけるリスク指標の監督・分析支援システムです。同銀行では既にリスク指標のデータベースを構築し、従来のBIシステムを用いて指標をクリック操作などで閲覧しています。近年では自然言語で指標を照会し、予測や要因分析、意思決定支援まで行う製品やソリューションも導入されています。しかし、顧客のニーズは指標データだけで完結するものではありません。多くの場合、指標に関連する法令や内部規定を示す文書が別部門から随時送付され、指標がこれらの規定に準拠しているかや、アルゴリズムの変更通知などが業務に影響を及ぼします。これらの文書情報が指標システムの出力結果と整合しないケースは現場で頻繁に発生しています。
こうした背景から、銀行側は指標の照会や分析において、文書解析を組み合わせた統合的な運用を求めました。たとえば「過去1ヶ月の不良債権比率は?」という問い合わせに対し、一般的なシステムなら「5.01%」という数字を返すのみですが、文書庫に「不良債権比率は5%を超えてはならない」という規定が含まれている場合は、その内容と出典を併せて提示し、業務担当者に注意喚起を行う必要があります。
本システムでは、先に紹介した融合ナレッジベースに指標データと関連文書を統合し、それらのメタデータや実データを抽出・整理します。大規模言語モデルによる指標分析時には、プロンプトで文書の関連警告や規定を参照するよう誘導し、該当する場合は自動的に注意喚起を返します。これにより、担当者は指標異常の根本原因や関連規制を即座に把握し、より適切で精度の高い意思決定が可能となっています。
まとめ
以上、RAG(Retrieval-Augmented Generation)についてご紹介させていただきました。弊社DXビジョンは、データサイエンティストとフルスタックエンジニアによる専門チームで、RAGをはじめとした最先端技術の開発・実装を得意としております。RAGの導入やPoC開発、システム連携など、ご興味やご相談がございましたら、ぜひ弊社の問い合わせフォームよりお気軽にご連絡ください。御社の課題解決に向けて、伴走させていただければ幸いです。
何卒よろしくお願いいたします。
\ 最新情報をチェック /

