生成AI導入の「最後の一マイル」を越える:DXビジョンの解
キーワード:生成AI導入, 企業AI, データ基盤, データガバナンス, RAG, AI-Readyデータ, 非構造化データ, データサイロ, ハルシネーション対策, データインテリジェンス

目次
- 生成AIの波で、企業導入が止まる「最後の一マイル」はどこか
- モデルの宴から「データ覚醒」へ
- データベースから「データインテリジェンス」へ
- AIの「消化不良」「ハルシネーション」を断つ三層アーキテクチャ
- ユースケース例
- 結び——私たちは「データ基盤の建築士」です
- よくある質問(FAQ)
生成AIの波で、企業導入が止まる「最後の一マイル」はどこか
— DXビジョンの視点:モデル競争から「AI-Readyなデータ」へ
企業の現場では、「PoC(概念実証)は通るのに、本番運用へ進めない」という声をよく耳にします。華やかな「モデルの性能競争」の陰で、実装は足踏み。絵に描いた餅で終わらせないための「最後の一マイル」は、実はデータにあります。
業界では「近い将来、ほとんどの企業が生成AIを本番導入する」といった予測が語られます。一方で、現実には多くのAI案件がPoC後に停滞。このギャップこそ、今の企業AIの最大の課題です。私たちDXビジョンは、多数の現場導入とベストプラクティスを通じて確信しています。
ボトルネックは「モデルの強さ」ではなく、「社内データを使い切れていないこと」。
モデルの宴から「データ覚醒」へ
モデルのパラメータを競い合うフェーズは峠を越え、「どんなデータで、どう運用するか」が勝負所です。
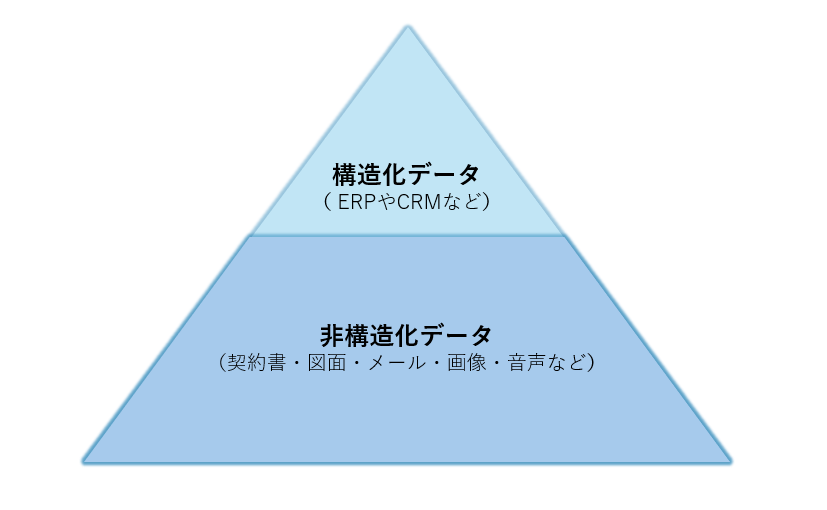
現場をのぞけば、典型的な「氷山の一角」問題が見えてきます。
- 水面上(約30%):ERPやCRMなどの構造化データは、従来の分析・レポートには有効
- 水面下(約70%):契約書・図面・メール・画像・音声などの非構造化データは、AI時代の「燃料」だが、部門やSaaSに点在しデータサイロ化
© 株式会社DXビジョン
データが分断されたままでは、いくら優秀なモデルでも脱線し、コア業務(計画、設計、製造、物流、与信・リスク、経営判断)に踏み込めません。結果として、適用範囲はFAQや要約など周辺業務に限定され、投資対効果(ROI)が伸びない——ここで多くのプロジェクトが止まります。
DXビジョンは、企業を「データ運び屋」から「データ建築士」へ。
モデル—データ—計算資源—アプリ—運用エコシステムを連動させることで、現場価値に直結させます。
データベースから「データインテリジェンス」へ
DXビジョンは創業当初から全員がデータサイエンティスト×フルスタックのマインドで、次世代データ基盤づくりに取り組んできました。鍵は「AI-Readyなデータ資産」をいかに素早く、正確に、そして安全に供給できるかです。
- データオペレーションに「知能」を付与
データエンジニア/サイエンティスト/データ管理者の生産性を、データ用エージェントで跳ね上げる。 - 統合データインテリジェンス基盤
モデル学習/推論に必要なデータを即時に探索・取得。マルチモーダル(表・テキスト・画像・音声)を一元ガバナンスし、評価→フィードバックの閉ループでハルシネーションを抑制。 - 「AI-Ready」変換の自動化
生データをクレンジング→分割→埋め込み→強化(RAGなど)まで自動で運び、使える形に整える。
AIの「消化不良」「ハルシネーション」を断つ三層アーキテクチャ
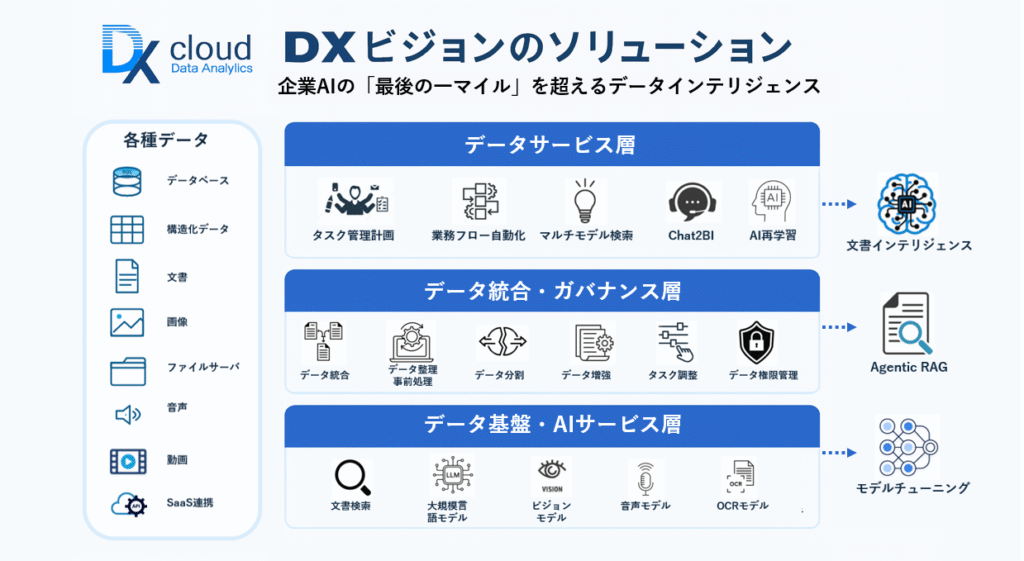
① 底層:全データの一元収容(スーパー収納箱)
データベースのテーブル、オブジェクトストレージのファイル、各種SaaSの情報……形式を問わず取り込み、単一のデータ空間に統合。
② 中間層:AIが「食べやすい形」に変換(AI-Ready化)
長文ドキュメントの分割・ベクトル化、メタデータ付与、アクセス制御、タスクスケジューリング、コンプライアンス(マスキング/監査ログ)まで一気通貫。RAGや評価指標で精度を継続改善。
③ 上層:ビジネス直結のアプリ群
- Copilot:現場業務の「最前線」で意思決定を支援
- Chat2BI:自然言語で即席BI(指示→可視化→再質問)
- マルチモーダル検索:販売DBと契約PDFをまたいで横断検索
- インテリジェント・ワークフロー:大量文書からの情報抽出・照合・起票まで自動化
ユースケース例
医療:全周期情報を見える化し、助言の的中率を向上
病歴・画像を統合し、NLPでキーデータを抽出。匿名化・追跡性を担保しながら学習データを強化。
患者の全ライフサイクル情報を自動で関連付け、診療支援の精度を高めます。

見積書・入札書作成:分断された知見を「再資源化」
製造業など大企業では、入札対応が重くて速くないのが通例。
DXビジョンの文書インテリジェンスで、仕様書の要件抽出→過去案件との照合→関連資格の自動マスキングまでを多エージェントで自動化。
想定効果:内容正確性の大幅向上(例:~90%を目標)、リードタイムを7–10日→1–2日へ短縮。点在していた知識を再利用可能なデジタル資産に格納します。

※効果は業種・データ状態・運用設計により変動します。
結び——私たちは「データ基盤の建築士」です
「モデルが強ければ勝てる」時代は終わり、「データをどう活かすか」が勝負です。
DXビジョンは、データフライホイール(収集→整備→活用→評価→改善の循環)を回し続け、AIをコア業務に使える水準へ押し上げます。日本の企業現場に根差したやり方で、海外の成功パターンの単純移植ではなく、現場実装からの逆算で価値を出す——それが私たちの流儀です。

お問い合わせ:コア業務での生成AI活用、RAG/評価設計、データガバナンスの内製化に関心があれば、ぜひご相談ください。
よくある質問(FAQ)
Q1. なぜPoCで止まるのですか?
A. データサイロ/品質ばらつき/権限設計の不備が多く、本番で再現できないためです。DXビジョンはAI-Readyな統合データ空間を先につくり、評価ループで改善を続けます。
Q2. ハルシネーション(事実誤認)をどう抑えますか?
A. 根拠付き回答(RAG)と評価→改善の閉ループが基本。プロンプト/テンプレートだけに頼らず、データ側の設計を厚くします。
Q3. 既存DWHやレイクはそのまま使えますか?
A. 可能です。既存資産の上にAI-Ready加工とポリシー統合を重ね、段階的な移行を推奨します。
Q4. まずは何から始めるべき?
A. 高頻度×反復性×判断コスト高な業務(例:入札・見積、品質照査、ナレッジ検索)を起点に、小さく回して早く学ぶのが近道です。
参考用:構造化・非構造化データのチェックリスト(抜粋)
- 主要SaaS/業務システムからの自動取り込みができる
- 文書は分割・埋め込み・メタ付与まで自動化
- アクセス権限/PIIマスキング/監査ログが標準装備
- RAG評価指標(正答率・根拠一致率・可読性)を運用
- ビジネスKPIとモデル評価を同じダッシュボードで追う
構造化データのあるある課題を「日本語で」言い換えると…
- 縦割りが強く、部門の壁を越えにくい
- データはあるが使える形に「こなれていない」
- 作って終わりの「やりっぱなし」で改善ループが回らない
DXビジョンは、この「企業現場の痛み」に即した運用設計まで含めて支援します。
© 株式会社DXビジョン — 本記事の内容・製品名は予告なく変更される場合があります。
\ 最新情報をチェック /

