業務に活かすDeep Research:その原理と価値

目次
- ご挨拶
- 「検索」と「リサーチ」の違いをご存知でしょうか?
- クエリ理解:AIの「質問の意図」を読み解く第一歩
- リサーチ・ループ:AIが考え、調べ、再び考える
- 情報の取得:検索の知性化
- ソース分析と情報統合
- システム構成と利用体験
- まとめ
ご挨拶
平素より大変お世話になっております。
株式会社DXビジョンでございます。
私たちは、データサイエンティストとフルスタックエンジニアによる精鋭チームとして、
AI技術の社会実装を迅速かつ実践的に推進しております。
「検索」と「リサーチ」の違いをご存知でしょうか?
検索は、答えをすぐに得るためにリンクを並べる行為です。一方でリサーチは、問いを深掘りし、複数の情報源を比較し、前提を疑いながら多角的に理解を深めていくプロセスです。これは一度きりではなく、答えからまた新しい問いが生まれる、反復的な知的活動です。従来のAIは、知識をただ記憶する存在にすぎませんでした。質問に対して訓練データに基づく情報を返すか、時には誤って創作してしまうこともありました。しかし、近年登場したAIアシスタントは、人間と同じようにリサーチを行えるようになってきています。
次世代AIは、問いを分解し、仮説を立て、事実を検証しながら情報を統合します。単なる情報検索ではなく、調査・検証・統合という「思考のプロセス」を持ち始めているのです。これによりAIは、静的な知識ベースから、動的な発見を行う存在へと進化しています。
本記事では、こうしたAIのリサーチ機能の原理を、アルゴリズムの視点から解説していきます。
クエリ理解:AIの「質問の意図」を読み解く第一歩
質問を入力して「Enter」を押した瞬間、AIは単なるキーワードの羅列ではなく、「何を知りたいのか」という意図そのものを読み取ろうとします。
これは、図書館の情報カウンターで、経験豊富な司書があなたの質問の本質を探ろうとするのと似ています。「特定の事実が知りたいのか?全体像の説明か?最新ニュースか?」といった目的をまず明確にします。AIも同じように、言葉の裏にあるニーズを理解しようとするのです。
たとえば「先週名前が変わった国の首都は?」と聞けば、AIは「これは最新の情報が必要だな」と判断し、リアルタイムでウェブ検索を行います。一方で、「月について詩を書いて」といった依頼には、外部情報は不要と判断してすぐに創作を始めます。
AIアシスタントは、質問の内容に応じて最適な処理ルートを選びます。Perplexityはクエリの意図に基づき検索の必要性を見極め、Grokはトレンド性の高い内容ならX(旧Twitter)まで検索範囲を広げます。一般的な知識で済む場合は、検索を行わずに即答します。
こうした「クエリ理解」は、AIがどのように情報探索を進めていくかを決める、最初の大切なステップです。
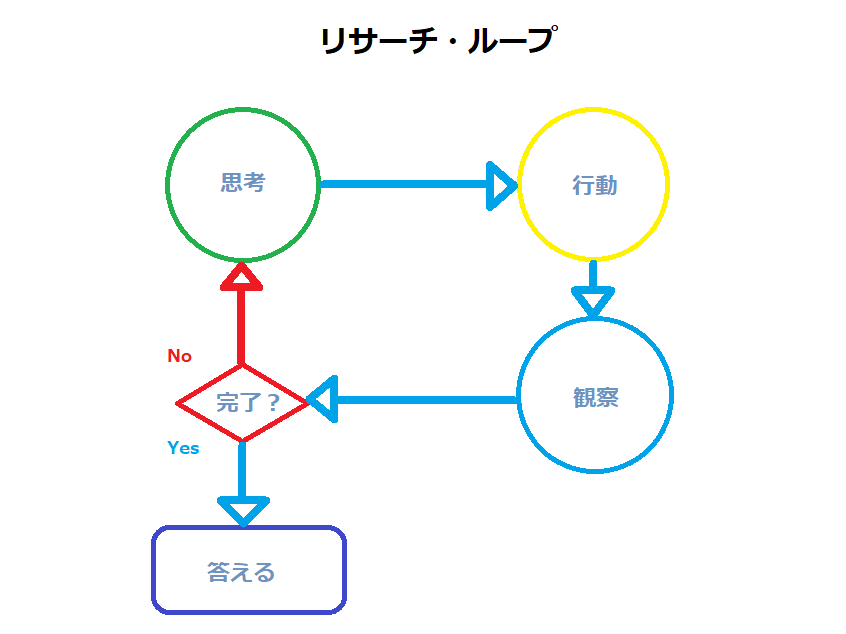
リサーチ・ループ:AIが考え、調べ、再び考える
AIが「これは外部情報が必要だ」と判断したとき、次に行うのが“リサーチ・ループ”です。これは「ReActパターン(Reason + Act)」と呼ばれ、人間のリサーチの進め方に非常によく似ています。
たとえば、あなたがある複雑な疑問に直面したとします。「まずはXについて調べよう。あ、Yも必要そうだな。XとYを合わせれば全体像が見えてくるぞ」と、段階的に思考と調査を繰り返しますよね。AIも同じように、思考と行動を高速で交互に繰り返しながら、情報を深掘りしていきます。
まず「思考(Reason)」──「ユーザーはChatGPTの最初の1年の成長について聞いている。まずはリリース時期を調べよう」と判断します。
次に「行動(Act)」──「ChatGPTのローンチ日とユーザー数」で検索を実行。
その後「観察(Observation)」──「2022年11月に公開、2か月で1億ユーザー達成」などの情報を得ます。
次の「思考」では、「1年全体の詳細データも必要だな」と考え、さらに検索を行います。
こうしてAIは、十分な情報を集めるまでこのループを何度も繰り返します。ReAct方式により、AIは「調べながら考える」ことができ、事実確認をせずに答えてしまう「幻覚(ハルシネーション)」を防ぐ効果もあります。
情報の取得:検索の知性化
リサーチ・ループの「Act(行動)」では、AIは高度な検索技術を活用して情報を取得します。従来のウェブ検索と、最新のAI技術が組み合わさった仕組みです。
賢い検索クエリの作成
AIアシスタントは、ユーザーの質問をもとに、効果的な検索クエリを自動生成します。質問があいまいな場合は、文脈を補ったり、具体的なキーワードを加えたりして、より適切な検索に調整します。このプロセスは、AIの「今、何を探すべきか」という思考に基づいています。
外部と内部の情報源
多くのAIアシスタントは、BingやGoogleなどの外部検索APIを利用して、最新の情報を取得します。一方、Perplexityのように独自のクローラー(PerplexityBot)でウェブ上の情報をインデックス化し、自社内に保持するタイプもあります。
ベクトル検索による高精度なマッチング
背後では「ベクトル検索」と呼ばれる技術が使われています。ウェブページの内容を数値化(ベクトル化)し、意味的に関連のある情報を素早く検索できるようにしています。たとえば「iPhone 15 バッテリー トラブル」という検索は、同じ単語を含まない記事でも、内容的に一致する情報を見つけられます。
結果の評価とフィルタリング
インターネット上の情報は玉石混交です。高度なAIアシスタントは、信頼性の高い情報を優先して表示するランキングアルゴリズムを使います。Perplexityは特に、SEO目的の記事や偏った情報を避け、学術論文や信頼あるニュースサイトを優先的に参照しています。
こうした選別によって、AIが提示する答えの質と信頼性が大きく高まっているのです。
ソース分析と情報統合
AIがWebページを「開く」と、対象の質問に関連する部分を瞬時に読み取り、要点を抽出します。まるで複数の文書を同時に超高速で検索するような仕組みです。たとえばWikipedia記事から特定の段落だけを要約するなど、必要な情報だけを的確に取り出します。
優れたAIリサーチアシスタントは、情報を単一のソースに頼らず、複数の出典を突き合わせて信頼性を確認します。複数の信頼できる情報源に同じ記述があれば、その内容はより確かなものと判断されます。
このように収集された事実をもとに、AIは分かりやすく一貫した回答を生成します。質問と関連情報をセットで言語モデルに渡し、「これが質問、これが出典A・B・Cからの情報。これを使って答えて」と指示する形です。
これが「Retrieval-Augmented Generation(RAG)」と呼ばれる仕組みで、モデルの知識を最新の外部情報で補強することで、事実に基づいた回答が可能になります。出典付きの回答は、透明性と信頼性も向上させます。
システム構成と利用体験
この種のAIアシスタントは、検索API、記事解析ツール、言語モデルなど複数の要素を組み合わせたシステムです。検索が必要と判断されると、適切なツールで検索・解析を行い、必要に応じて高速なモデルと高精度なモデルを使い分けます。
その結果、以下のようなユーザーメリットが得られます:
- 最新情報への対応:直近のニュースやイベントもリアルタイムでカバー。
- 高い正確性と低い幻覚率:記憶ではなく、実際のソースに基づいた回答。
- 出典の明示:情報の裏付けが明確で安心。
- 文脈に合った応答:質問内容に応じて最適な情報を抽出。
- 高速なレスポンス:複雑な処理を経ても、スムーズな返答速度。
このように、RAG型AIは従来型の言語モデルよりもはるかに信頼性の高いリサーチ支援を実現します。
まとめ
以上、Deep Researchの原理と価値についてご紹介させていただきました。弊社DXビジョンは、データサイエンティストとフルスタックエンジニアによる専門チームであり、最先端技術の開発・実装を得意としております。AIエージェントの導入支援や機械学習PoC開発、システム連携に関するご相談がございましたら、ぜひ弊社問い合わせフォームよりお気軽にご連絡ください。御社の課題解決に向けて、共に伴走できることを心より願っております。
何卒よろしくお願い申し上げます。
\ 最新情報をチェック /
